Перевод статьи How to Use Proxies to Rotate IP Addresses in Python.
В этой статье, мы научимся выполнять парсинг веб-сайтов, не позволяя им блокировать наш IP-адрес с помощью различных методов, использующих прокси в Python.
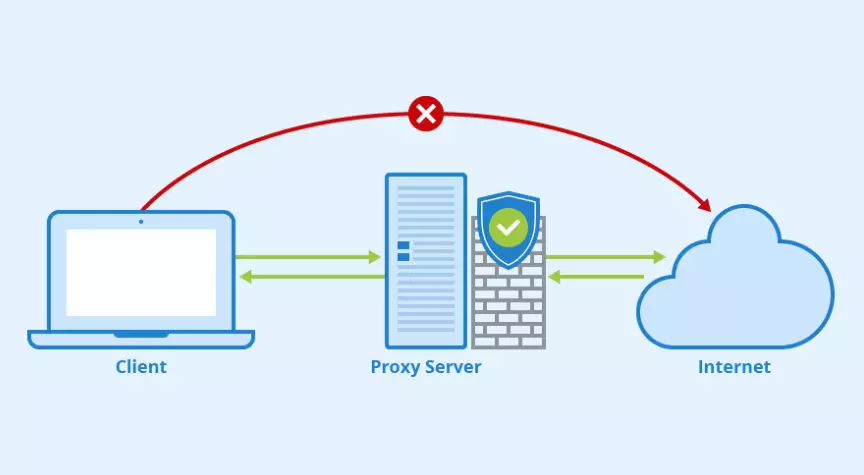
Прокси это сервер, на котором запущены специальные приложения, что позволяет ему выступать в качестве посредника при обмене запросами ( HTTP , SSL и т.д.) между клиентом и определенным целевым сервером.
Другими словами при использовании прокси-сервера вместо прямого подключения к целевому серверу и отправки запроса ему непосредственно, вы направляете запрос на прокси-сервер, который обрабатывает его, выполняет его и возвращает ответ. Рисунок ниже демонстрирует, проще чем в Википедии, принцип работы прокси-сервера:
Специалисты по парсингу часто используют более одного прокси, чтобы веб-сайты не блокировали их IP-адрес. Кроме того прокси-серверы имеют ряд других преимуществ, в том числе обход различных фильтров и цензуры, скрытие вашего реального IP-адреса и т.д.
В этом руководстве вы узнаете, как использовать прокси-серверы в Python с помощью библиотеки requests, мы также будем использовать библиотеку stem, библиотекой позволяющей работать с помощью Python контролером Tor, то есть программно отправлять и получать от него команды. Также мы будем использовать библиотеку BeautifulSoup для обработки полученного содержимого страниц. И так давайте установим их:
pip3 install bs4 requests stem
Содержание
Используем адреса активных бесплатных прокси
В сети есть несколько веб-сайтов, которые предлагают бесплатный список прокси-серверов. И я создал функцию для автоматического получения их списка:
import requests
import random
from bs4 import BeautifulSoup as bs
def get_free_proxies():
url = "https://free-proxy-list.net/"
# посылаем HTTP запрос и создаем soup объект
soup = bs(requests.get(url).content, "html.parser")
proxies = []
for row in soup.find("table", attrs={"id": "proxylisttable"}).find_all("tr")[1:]:
tds = row.find_all("td")
try:
ip = tds[0].text.strip()
port = tds[1].text.strip()
host = f"{ip}:{port}"
proxies.append(host)
except IndexError:
continue
return proxies
Однако, когда я попытался использовать их, у большинства из них был слишком большой тайм-аут, и я отфильтровал только рабочие:
proxies = [
'167.172.248.53:3128',
'194.226.34.132:5555',
'203.202.245.62:80',
'141.0.70.211:8080',
'118.69.50.155:80',
'201.55.164.177:3128',
'51.15.166.107:3128',
'91.205.218.64:80',
'128.199.237.57:8080',
]
Этот список может оказаться весьма недолговечным, так как большинство из адресов перестанут работать, уже когда вы прочтете это руководство (поэтому вам следует выполнять указанную выше функцию каждый раз, когда вам понадобятся новые адреса прокси-серверов).
Следующая функция принимает список адресов прокси-серверов, создает новый объект session, а также случайным образом выбирает один из переданных в нее адресов прокси для последующей отправки запросов:
def get_session(proxies):
# создаем сессию для отправки HTTP запроса
session = requests.Session()
# выбираем случайным образом один из адресов
proxy = random.choice(proxies)
session.proxies = {"http": proxy, "https": proxy}
return session
Давайте проверим этот код, отправив запрос на веб-сайт, который возвращает наш IP-адрес:
for i in range(5):
s = get_session(proxies)
try:
print("Request page with IP:", s.get("http://icanhazip.com", timeout=1.5).text.strip())
except Exception as e:
continue
В результате получим:
Request page with IP: 45.64.134.198 Request page with IP: 141.0.70.211 Request page with IP: 94.250.248.230 Request page with IP: 46.173.219.2 Request page with IP: 201.55.164.177
Как видите, это IP-адреса рабочих прокси-серверов, а не наш реальный IP-адрес (попробуйте посетить этот веб-сайт в своем браузере, и вы увидите свой реальный IP-адрес).
Бесплатные прокси, как правило, умирают очень быстро, в основном за дни или даже часы. Поэтому вам необходимо использовать прокси-серверы премиум-класса для крупномасштабных проектов по извлечению данных, для этого существует множество провайдеров, которые меняют ваши IP-адреса. Одно из хорошо удобных решений – сервис Crawlera . Мы поговорим об этом подробнее в последнем разделе этого руководства.
Использование Tor в качестве прокси
Вы также можете использовать сеть Tor для ротации IP-адресов:
import requests
from stem.control import Controller
from stem import Signal
def get_tor_session():
# создаем сессию для отправки HTTP запроса
session = requests.Session()
# настраиваем прокси для запросов http & https через localhost:9050
# эти настройки необходимы для запуска сервиса Tor на вашем компьютере
# прослушивания по умолчанию порта 9050
session.proxies = {"http": "socks5://localhost:9050", "https": "socks5://localhost:9050"}
return session
def renew_connection():
with Controller.from_port(port=9051) as c:
c.authenticate()
# посылаем сигнал NEWNYM signal для создания нового подключения к сети Tor
c.signal(Signal.NEWNYM)
if __name__ == "__main__":
s = get_tor_session()
ip = s.get("http://icanhazip.com").text
print("IP:", ip)
renew_connection()
s = get_tor_session()
ip = s.get("http://icanhazip.com").text
print("IP:", ip)
Примечание. Приведенный выше код должен работать только в том случае, если на вашем компьютере установлен Tor (перейдите по этой ссылке, чтобы правильно установить его) и правильно настроен (включен ControlPort 9051, см. этот ответ в stackoverflow о переполнении стека для получения дополнительных сведений).
Этот код создает новую сессию с IP-адресом Tor и отправляет HTTP запрос, а затем обновляет соединение, отправив в сеть сигнал NEWNYM (который сообщает Tor, что устанавливается новое соединение), чтобы изменить IP-адрес и делает следующий запрос. В результате получим:
IP: 185.220.101.49 IP: 109.70.100.21
Все получилось. Однако, когда вы попробуете веб-парсинг с использованием сети Tor, вы скоро поймете, что в большинстве случаев это довольно медленно, поэтому рекомендуемый мною способ мы рассмотрим ниже.
Используем Crawlera
Crawlera от Scrapinghub позволяет вам осуществлять парсинг быстро и надежно, управляя прокси-серверами, автоматически меняя их адреса, поэтому, если вас забанят, он автоматически обнаружит это и изменит IP-адрес за вас.
Crawlera — это интеллектуальная прокси-сеть, специально разработанная для парсинга и сканирования веб-страниц. Ее задача проста: облегчить вам жизнь в качестве парсера. Она помогает получать успешные запросы и извлекать данные в любом масштабе с любого веб-сайта с помощью любого инструмента для разбора содержимого веб-страниц.
Благодаря простому API запрос, который вы делаете при парсинге, будет маршрутизироваться через пул высококачественных прокси. При необходимости он автоматически вводит задержки между запросами и удаляет/добавляет IP-адреса для решения различных проблем сканирования.
Вот как можно использовать Crawlera с библиотекой requests используя Python:
import requests url = "http://icanhazip.com" proxy_host = "proxy.crawlera.com" proxy_port = "8010" proxy_auth = ":" proxies = { "https": f"https://{proxy_auth}@{proxy_host}:{proxy_port}/", "http": f"http://{proxy_auth}@{proxy_host}:{proxy_port}/" } r = requests.get(url, proxies=proxies, verify=False)
После регистрации вам будет предоставлен ключ API, которым вы замените строку proxy_auth.
Итак, вот что делает для вас Crawlera:
- Вы отправляете HTTP-запрос, используя API через единую конечную точку.
- Автоматически выбирает, меняет, ограничивает и заносит в черный список нерабочие IP-адреса для получения целевых данных.
- Обрабатывает заголовки запросов и поддерживает механизм сессий.
- В ответ вы всегда получаете успешный запрос и соответственно содержимое целевой страницы.
Заключение
Существует несколько типов прокси, включая прозрачные прокси, анонимные прокси, «элитные» прокси. Если ваша цель использования прокси, чтобы не дать веб-сайтам блокировать ваши парсеры, то «элитные» прокси ваш оптимальный выбор.
Кроме того, дополнительной мерой защиты от блокирования ваших парсеров является использование ротации типов и свойств пользовательских агентов user agents. То есть вы каждый раз должны отправлять новый поддельный заголовок запроса, имитируя браузер обычного пользователя.






Одна из лучших статей про парсинг, что я видел, даже учитывая англоязычные источники)
Спасибо.